

Published: 7/9/2024

Don Simons
EVP, North American Sales, Dynata
What is ‘Synthetic Sampling’?
Synthetic sampling is a technique utilized in market research to generate data through the simulation of responses or scenarios by computer algorithms, particularly leveraging Large Language Models (LLMs). This method involves creating artificial data that mimics real-world responses or behaviors, offering insights into consumer preferences, opinions, and trends without relying solely on traditional survey methods or human panels. After analyzing existing human datasets, AI-powered synthetic data generators can develop data that maintain the statistical properties of their “real” counterparts. Synthetic data is entirely artificial and created by generative algorithms.
Why So Much Buzz Now?
In Market Research, we have been filling in ‘missing data,’ “ascribing’ data, and fueling ‘what if’ scenario tools for a long time. Today’s synthetic sample is an extension of this capability- more powerful and scalable, but not a wholesale new development as current conversation often makes it sound. It’s an important reminder as we evaluate the utility and application of this capability that this is not a new solution.
There are certainly appropriate use cases today, and I expect more to come. But we need to be careful about jumping to irrational conclusions based solely on excitement. Like many new developments, integrating it responsibly into our market research tool kit will be key. Ignore the current hyperbole stating that ‘synthetic data is all you need.’
The hype is being fed by articles like Mark Ritson’s recent piece in Marketing Week on June 13, where he argues that synthetic data is as good as real. I have no doubt that in some cases it can be, but having ALL and ONLY synthetic data is impossible- there must be seed data to train a model, and that data must be authentically from the voice of the consumer.
Despite all the existing concerns, Gartner predicts that by 2030 (6 years away!) most of the data used in AI will be synthetic data.
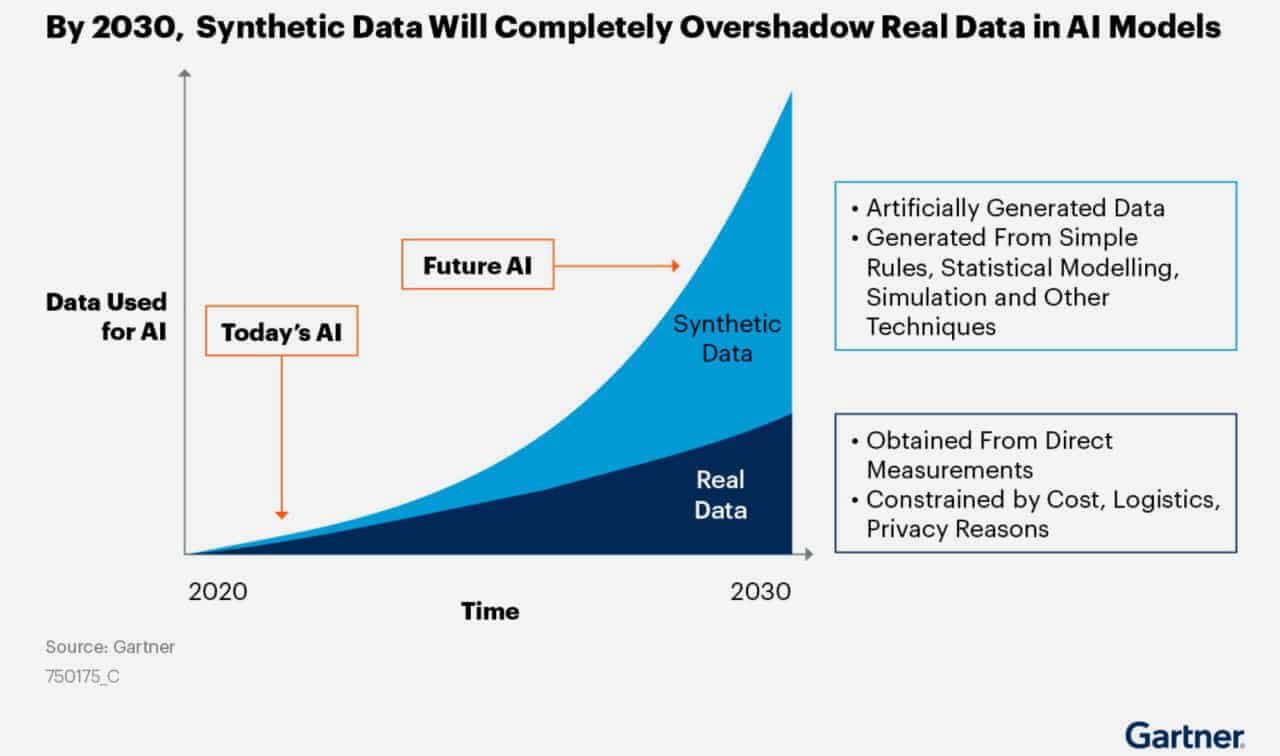
Is it Really Ready for Prime Time?
As my colleague @Steven Millman has said: “Synthetic panels can be beneficial in producing simulations, where underlying assumptions are applied to a population. For example, a company with consumer data could use an LLM to fill gaps and explore “what-if” scenarios based on assumptions, but acknowledging underlying biases is crucial. For small amount of missing data, AI and LLM models can be useful for filling in the blanks. However, data quality is important for producing accurate results due to the risk of producing reductive, regressive, or prejudiced responses if the underlying data is flawed. Additionally, AI models have proven useful as coding co-pilots, assisting developers in writing and refining code efficiently.”
The concerns I have that need more testing include:
- The models rely on potentially flawed or biased data sources and these biases need to at least be understood. Cathy O’Neil’s Weapons of Math Destruction highlighted this concern in 2016.
- They are trained on past behaviors; when significant events occur that change consumer behavior – think of pre- and post- COVID, the backward-looking analysis is far less useful.
- Models are limited by their training sets – for example, ChatGPT’s training set is two years old, and would not know about new products, current events, or even who is running for President now.
- This places ever more importance on ensuring the training set data is of the highest quality and is truly a source of truth- making the source data transparent to anyone using the synthetic data will be critical.
- AI models have been shown to hallucinate, making things up wholesale, and we do not really understand why.
I’m certainly excited about the early application and possibility of synthetic sample- especially being able to provide more robust data against extremely hard to find (and therefore measure) audiences. But we must do responsibly- and note this does not mean ‘fight it’ but rather ensure objective evaluation.
Now What
Most of the applications need more testing, and we must demonstrate that testing and training is done on proven, quality data. A recent comment from Nik Samoylov on LinkedIn summarizes the bar we must clear well: “People who are pushing synthetic data for market research should ask themselves “Do you want to replace voters at elections with synthetic votes?”. If you can’t do it (and hopefully they agree you can’t), then you can’t use synthetic data instead of meaningful, original primary research.”
At Dynata we use machine learning and LLM’s in numerous ways, specifically to ensure our data quality and continue to evolve our own best practices approach as innovative technology becomes available. We are always pleased to participate in industry-wide discussions and to help advise our customers as we learn.